
做语料交易平台,Cloudflare要为站长“主持公道”
大模型遭遇数据荒这件事,已经从遥遥领先的预言变成了一个所有AI厂商都不得不面对的难题。为了解决这个问题,谷歌前CEO埃里克・施密特更是曾语出惊人,表示AI创业公司可以先通过AI工具盗取知识产权,然后再雇佣律师来处理法律纠纷。但就在AI行业出现“语料危机”的兵荒马乱里,也有厂商发现了商机。

日前,全球知名的内容分发网络(CDN)Cloudflare宣布将在明年推出交易市场,允许AI公司付费获取网站内容的抓取权限。据Cloudflare方面的描述,网站运营者可以将自己的网站放在这个市场中,如果有AI开发商愿意付费购买其内容,则可以向后者提供接口以供抓取网站的内容用于AI大模型的训练。
进入2024年之后,随着Common Crawl数据集、The Pile语料库等开源数据库的开发殆尽,AI厂商在获取语料数据这件事上也完全可以用“吃相难看”来形容。例如苹果、英伟达、OpenAI在训练大模型时使用了YouTube未经授权的数据,AI独角兽Anthropic更是直接分布式拒绝服务攻击(DDoS)小网站等让人大跌眼镜的操作,也开始堂而皇之的出现。

当然,除了这些上不得台面的玩法之外,业界也在尝试用“合成数据”来训练大模型,试图用这种“左脚踩右脚上天”的模式来使得大模型摆脱对于语料数据的依赖。可惜随着一篇《Nature》上的论文问世,使用AI生成的数据集训练大模型会污染它们的输出,无法避免“模型崩溃”(model collapse)的缺陷,也让合成数据这条路径的未来蒙上了阴影。
展开全文
如此一来,向内容方索取数据就又变成了AI厂商的唯一选项。现在的情况,是AI厂商对于数据的需求永无止境,但他们需要将有限的预算花在算力、电力、水资源等刚性需求的资源上,以至于“偷数据”就变成了一个降本增效的手段。同时,一般的网站虽然有数据、但也缺乏保护数据的能力。
站在网站站长的角度,一方面自己网站的内容被AI厂商无偿抓取,另一方面AI厂商爬虫进行的高频次抓取已经与DDoS没区别了,导致自己还要付出更高的带宽和流量清洗成本。由此不愿付钱的AI厂商与想要将数据卖个好价钱的内容方之间,自然也就产生了不可调和的矛盾。
这时候,双方都需要一个类似Cloudflare这样的角色站出来当“裁判员”。作为CDN提供商,Cloudflare的竞争力来源于在全球拥有超过152个数据中心,这些数据中心战略性地分布在全球各地,以确保其业务覆盖所有主要地区,再加出色的网络技术,也使得全世界目前有20%的互联网流量都经过了该公司的网络代理。

为了向用户提供高速网络服务,Cloudflare建设了一个专用的高容量光纤网络,用于在全球的数据中心之间传输流量,这也使得其能够完全控制内部和外部流量的路由,以便更有效地管理流量。而为全球中小网站提供一个低成本接入公开网络的能力,这就是Cloudflare的底气。
就如同谷歌提供了一个广告竞价平台,得以让全球的站长通过经营网站获得收入一样,Cloudflare现在就是打算复刻谷歌曾经的做法,建立一个内容拍卖平台,让AI厂商像广告主一样为他们感兴趣的内容付费。毕竟全球1/5的流量会经过Cloudflare的分发网络,所以也意味着后者确实也拥有类似谷歌搜索引擎的地位。
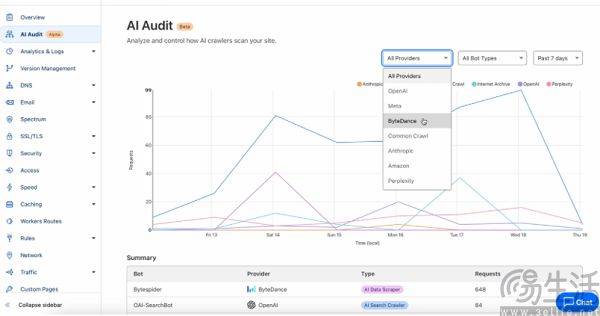
与此同时,为了保证这个交易市场得以运行下去,Cloudflare还宣布为使用其服务的所有网站,包括免费托管在Cloudflare上的网站提供AI审计工具 (Cloudflare AI Audit) ,从而向网站站长报告AI厂商的爬虫何时访问网站、抓取数据的IP地址、抓取频次,以及其他相关数据。
借助AI审计工具,哪些AI厂商尝试抓取了网站的数据也就变得一目了然。并且为了配合这个交易市场,Cloudflare方面表示AI审计工具与目前为站长提供的一键屏蔽AI爬虫功能不同,其提供了更灵活的屏蔽策略。比如说,一旦某网站与OpenAI达成合作,站长就可以单独为OpenAI的GPTBot提供“绿色通道”。
不得不说,作为业界知名的“赛博菩萨”,Cloudflare确实是想用户之所想、急用户之所急,这样一套组合拳打下去,AI厂商大概率就会乖乖地向网站站长付费了。








评论